当前期刊数: 123
1 引言
在写这次精读之前,我想谈谈前端精读可以为读者带来哪些价值,以及如何评判这些价值。
前端精读已经写到第 123 篇了,大家已经不必担心它突然停止更新,因为我已养成每周写一篇文章的习惯,而读者也养成了每周看一篇的习惯。所以我想说的其实是一种更有生命力的自媒体运作方式,定期更新。一个定期更新的专栏比一个不不定期更新的专栏更有活力,也更受读者喜爱,因为读者能看到文章之间的联系,跟随作者一起成长。个人学习也是如此,养成定期学习的习惯,比在培训班突击几个月更有用,学会在生活中规律的学习,甚至好过读几年名牌大学。
前端精读想带给读者的不仅是一篇篇具体的内容和知识,知识是无穷无尽的,几万篇文章也说不完,但前端精读一直沿用了“引言-概述-精读-总结”这套学习模式,无论是前端任何领域的问题,还是对人生和世界的思考都可以套用,希望能为读者提供一套学习思维框架,让你能学习到如何找到好的文章,以及如何解读它。
至今已经选择了许多源码解读的题材,与培训思维的源码解读不同,我希望你不要带着面试的目的学习源码,因为这样会让你只局限在 react、vue 这种热门的框架上。前端精读选取的框架类型之所以广泛,是希望你能静下心来,吸取不同框架风格与作者的优势,培养一种优雅编码的气质。
进入正题,这次选择的文章 《用 Babel 创造自定义 JS 语法》 也是培养编码气质的一类文章,虽然对你实际工作用处不大,但这篇文章可以培养几个程序员梦寐以求的能力:深入理解 Babel、深入理解框架拓展机制。理解一个复杂系统或培养框架思维不是一朝一夕的,但持续阅读这种文章可以让你越来越接近掌握它。
之所以选择 Babel,是因为 Babel 处理的一直是语法树相关的底层逻辑,编译原理是程序世界的基座之一,拥有很大的学习价值。所以我们的目的并不是像文章标题说的 - 创造一个自定义 JS 语法,因为你创造的语法只会让 JS 复杂体系更加混乱,但可以让你理解 Babel 解析标准 JS 语法的原理,以及看待新语法提案时,拥有从实现层面思考的能力。
最后,不必多说,能重温 Babel 经典的插件机制,你可以发现 Babel 的插件拓展机制和 Antrl4 很像,在设计业务模块拓展方案时也可以作为参考。
2 概述
我们要利用 Babel 实现 function @@ 的新语法,用 @@ 装饰的函数会自动柯里化:
1 | |
可以看到,function @@ foo 描述的函数 foo 支持 foo(1, 2)(3) 这种柯里化调用。
实现方式分为两步:
- Fork babel 源码。
- 创建一个 babel 转换器插件。
不要畏惧这些步骤,“如果你读完了这篇文章,你将成为同事眼中的 Babel 大神” - 原文。
首先 Fork babel 源码到本地,执行下面的命令可以初始化并编译 babel:
1 | |
babel 使用 Makefile 执行编译命令,并且采用 monorepo 管理,我们这次要关心的是 package/babel-parser 这个模块。
词法
首先要了解词法知识,更详细的可以阅读原文或精读之前的一篇系列文章:精读《词法分析》。
要解析语法,首先要进行词法分析。任何语法输入都是一个字符串,比如 function @@ foo(a, b, c),词法分析就是要将这个长度为 24 的字符拆分为一个个有语义的单词片段:function @@ foo ( a ..
由于 @@ 是我们创造的语法,所以我们第一个任务就是让 babel 词法分析可以识别它。
下面是 package/babel-parser 的文件结构:
1 | |
可以看到,分为词法分析 tokenizer,语法分析 parser,以及支持一些特殊语法的插件,以及测试用例 test。
推荐使用 Test-driven development (TDD) - 测试驱动开发的方式,就是先写测试用例,再根据测试用例开发。这种开发方式在后端或者 babel 这种底层框架很常见,因为 TDD 方式开发的逻辑能保证测试用例 100% 覆盖,同时先看测试用例也是个很好的切面编程思维。
1 | |
可以利用 jest 直接测试这段代码:
1 | |
结果会出现如下报错:
1 | |
第 9 个字符就是 @,说明程序现在还不支持函数前面的 @ 解析。我们还可以在错误堆栈中找到报错位置,并把当前 Token 与下一个 Token 打印出来:
1 | |
this.state.type 代表当前 Token,this.lookahead().type 表示下一个 Token。lookahead 是词法分析的专有词,表示向后查看。打印之后,我们会发现输出了两个 @ Token:
1 | |
下一步,我们需要让 babel 词法分析识别 @@ 这个 Token。首先需要注册这个 Token:
1 | |
注册了之后,我们要在遍历 Token 时增加判断 “如果当前字符是 @ 且下一个字符也是 @,则整体构成了 @@ Token 并且光标向后移动两格”:
1 | |
再次运行测试文件,输出变成了:
1 | |
到这一步,已经能正确解析 @@ Token 了。
语法
词法已经可以将 @@ 解析为 atat Token,下一步我们就要利用这个 Token,让生成的 AST 结构中包含柯里化函数的信息,并利用 babel 插件在解析时实现柯里化功能。
首先我们可以在 Babel AST explorer 看到 AST 解析的结构,我们拿 generator 函数测试,因为这个函数结构与柯里化函数类似:

可以看到,babel 通过 generator async 属性来标识函数是否为 generator 或者 async 函数。同理,增加一个 curry 属性就可以实现第一步了:
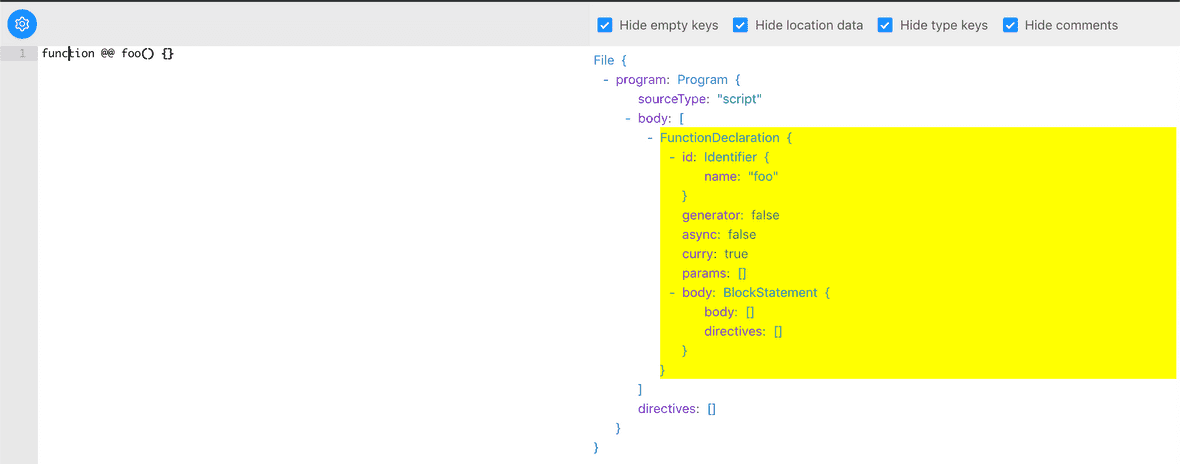
要实现如上效果,只需在词法分析 parser/statement 文件的 parseFunction 处新增 atat 解析即可:
1 | |
eat 是吃掉的意思,实际上可以理解为吞掉这个 Token,这样做有两个效果:1. 为函数添加了 curry 属性 2. 吞掉了 @@ 标识,保证所有 Token 都被识别是 AST 解析正确的必要条件。
关于递归下降语法分析的更多知识,可以参考 精读《手写 SQL 编译器 - 语法分析》,或者阅读原文。
我们再次执行测试函数,发现测试通过了,一切都在预料中。
babel 插件
现在我们得到了标记了 curry 的 AST,那么最后需要一个 babel 解析插件,实现柯里化。
首先我们通过修改 babel 源码的方式实现的效果,是可以转化为自定义 babel parser 插件的:
1 | |
这样就可以实现修改 babel 源码一样的效果,这也是做框架常用的插件机制。
其次我们要理解如何实现柯里化。柯里化可以通过柯里函数包装后实现:
1 | |
柯里化函数通过构造参数数量相关的递归,当参数传入不足时返回一个新函数,并持久化之前传入的参数,最后当参数齐全后一次性调用函数。
我们需要做的是,将 @@ foo 解析为 currying() 函数包裹后的新函数。
下面就是我们熟悉的 babel 插件部分了:
1 | |
FunctionDeclaration 就是 AST 的 visit 钩子,这个钩子在执行到函数时被触发,我们通过 path.get('curry') 拿到 柯里化函数,并利用 replaceWith 将这个函数构造为一个被 currying 函数包裹的新函数。
剩下最后一个问题:currying 函数源码放在哪里。
第一种方式,创建类似 babel-plugin-transformation-curry-function 这样的插件,在 babel 解析时将 currying 函数注册到全局,这是全局思维的方案。
第二种是模块化解决方案,创建一个自定义的 @babel/helpers,注册一个 currying 标识:
1 | |
在 visit 函数使用 addHelper 方式拿到 currying:
1 | |
这样在 babel 转换后,就会自动 import helper,并引用 helper 中导出的 currying。
最后原文末尾留下了一些延伸阅读内容,感兴趣的同学可以 点击到原文。
3 精读
读完这篇文章,相信你不仅对 babel 插件有了更深刻的认识,而且还掌握了如何为 js 添加新语法这种黑魔法。
我来帮你从 babel 这篇文章总结一些编程模型和知识点,借助 babel 创造自定义语法的实例,加深对它们的理解。
TDD
Test-driven development 即测试驱动的开发模式。
从文章的例子可以看出,创造一个新语法,可以先在测试用例先写上这个语法,通过执行测试命令通过报错堆栈一步步解决问题。这种方式开发可以让测试覆盖率更高,目的更专注,更容易保障代码质量。
联想编程
联想编程不属于任何编程模型,但从简介的思路来看,作者把 “为 babel 创建一个新 js 语法” 看作一种探案式探索过程,通过错误堆栈和代码阅读,一步一步通过合理联想实现最终目的。
在 AST 那一节,还借助了 Babel AST explorer 工具查看 AST 结构,通过联想到 generator 函数找到类似的 AST 结构,并找到拓展 AST 的突破口。
随着解决问题的不同,联想方式也不同,如果能够举一反三,对不同场景都能合理的联想,才算是具备了技术专家的软素质。
词法、语法分析
词法、语法分析属于编译原理的知识,理解词法拆分、递归下降,可以帮助你技术走的更深。
不论是 Babel 插件的使用、还是 Babel 增加自定义 JS 语法,都要具备基本编译原理知识。编译原理知识还能帮助你开发在线编辑器,做智能语法提示等等。
插件机制
如下是 babel 自定义 parser 的插件拓展方式:
1 | |
这只是插件拓展的一种,有申明式,也有命令式;有用 JS 书写的,也有用 JSON 书写的。babel 选择了通过对象方式拓展,是比较适合对 AST 结构统一处理的。
做框架首先要确定接口规范,比如 parser,先按照接口规范实现一套官方解析,对接时按照接口进行对接,就可以自然而然被用户自定义插件替代了。
可以参考的文章: 精读《插件化思维》
柯里化
柯里化是面试经常考察的一个知识点,我们能学到的有两点:理解递归、理解如何将函数变成柯里化。
这里再拓展一下,我们还可以想到 JS 尾递归优化。如何快速写一个支持尾递归的函数?
1 | |
通过封装 tailCallOptimize 函数,可以很方便的构造一个支持尾递归的函数,这个函数可以这么写:
1 | |
感兴趣的读者可以在评论里解释一下这个函数的原理。
AST visit
遍历 AST 树常采用的方案是做一个遍历器 visitor,所以在遍历过程中进行拓展常采用 babel 这种方式:
1 | |
visitor 下每一个 key 名都是遍历过程中的拓展点,比如上面的例子,我们可以对函数定义位置进行拓展和改写。
内置函数注册
babel 提供了两种内置函数注册方式,一种类似 polyfill,在全局注册 window 级的变量,另一种是模块化的方式。
除此之外,可以学习的是 babel 通过 this.addHelper("currying") 这种插件拓展方式,在编译后会自动从 helper 引入对应的模块,前提是 @babel/helper 需要注册 currying 这个 helper。
babel 将编译过程隐藏了起来,通过一些高度封装的函数调用,以较为语义化方式书写插件,这样写出来的代码也容易理解。
4 总结
《用 Babel 创造自定义 JS 语法》这篇文章虽然说的是 babel 相关知识,但可以从中提取到许多通用知识,这就是现在还去理解 babel 的原因。
从某个功能点为切面,走一遍框架的完整流程是一种高效的进阶学习方式,如果你也有看到类似这样的文章,欢迎推荐出来。
如果你想参与讨论,请 点击这里,每周都有新的主题,周末或周一发布。前端精读 - 帮你筛选靠谱的内容。
关注 前端精读微信公众号

版权声明:自由转载-非商用-非衍生-保持署名(创意共享 3.0 许可证)