当前期刊数: 194
掌握了不同数据结构的特点,可以让你在面对不同问题时,采用合适的数据结构处理,达到事半功倍的效果。
所以这次我们详细介绍各类数据结构的特点,希望你可以融会贯通。
精读
数组
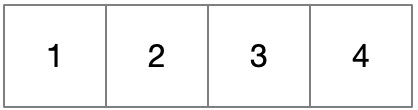
数组非常常用,它是一块连续的内存空间,因此可以根据下标直接访问,其查找效率为 O(1)。
但数组的插入、删除效率较低,只有 O(n),原因是为了保持数组的连续性,必须在插入或删除后对数组进行一些操作:比如插入第 K 个元素,需要将后面元素后移;而删除第 K 个元素,需要将后面元素前移。
链表

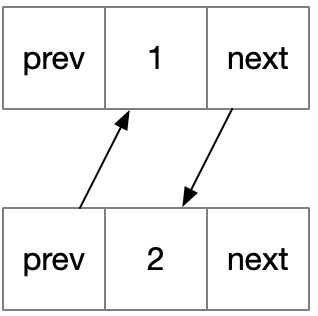
链表是为了解决数组问题而发明出来的,它提升了插入、删除效率,而牺牲了查找效率。
链表的插入、删除效率是 O(1),因为只要将对应位置元素断链、重连就可以完成插入、删除,而无需关心其他节点。
相应的查找效率就低了,因为存储空间不是连续的,所以无法像数组一样通过下标直接查找,而需要通过指针不断搜索,所以查找效率为 O(n)。
顺带一提,链表可以通过增加 .prev 属性改造为双向链表,也可以通过定义两个 .next 形成二叉树(.left .right)或者多叉树(N 个 .next)。
栈
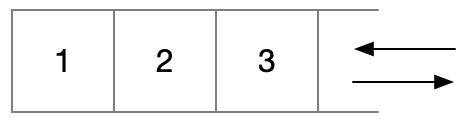
栈是一种先入后出的结构,可以用数组模拟。
1 | |
堆
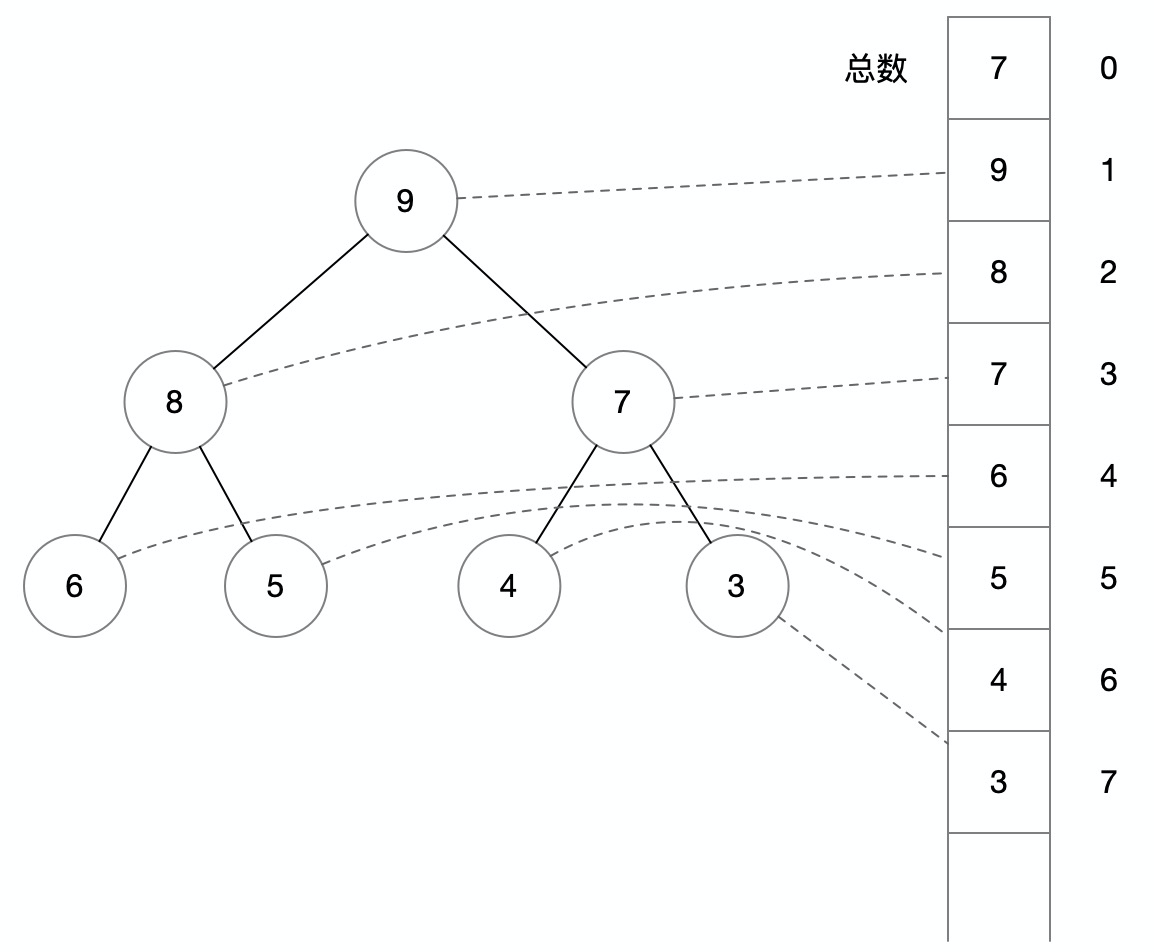
堆是一种特殊的完全二叉树,分为大顶堆与小顶堆。
大顶堆指二叉树根节点是最大的数,小顶堆指二叉树根节点是最小的数。为了方便说明,以下以大顶堆举例,小顶堆的逻辑与之相反即可。
大顶堆中,任意节点都比其叶子结点大,所以根节点是最大的节点。这种数据结构的优势是可以以 O(1) 效率找到最大值(小顶堆找最小值),因为直接取 stack[0] 就是根节点。
这里稍微提一下二叉树与数组结构的映射,因为采用数组方式操作二叉数,无论操作还是空间都有优势:第一项存储的是节点总数,对于下标为 K 的节点,其父节点下标是 floor(K / 2),其子节点下标分别是 K * 2、K * 2 + 1,所以可以快速定位父子位置。
而利用这个特性,可以将插入、删除的效率达到 O(logn),因为可以通过上下移动的方式调整其他节点顺序,而对于一个拥有 n 个节点的完全二叉树,树的深度为 logn。
哈希表
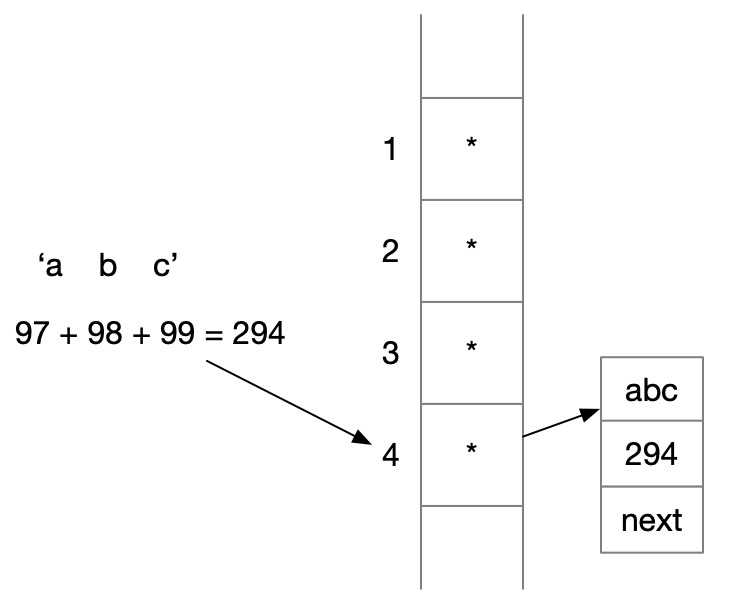
哈希表就是所谓的 Map,不同 Map 实现方式不同,常见的有 HashMap、TreeMap、HashSet、TreeSet。
其中 Map 和 Set 实现类似,所以以 Map 为例讲解。
首先将要存储的字符求出其 ASCII 码值,再根据比如余数等方法,定位到一个数组的下标,同一个下标可能对应多个值,因此这个下标可能对应一个链表,根据链表进一步查找,这种方法称为拉链法。
如果存储的值超过一定数量,链表的查询效率就会降低,可能会升级为红黑树存储,总之这样的增、删、查效率为 O(1),但缺点是其内容是无序的。
为了保证内容有序,可以使用树状结构存储,这种数据结构称为 HashTree,这样时间复杂度退化为 O(logn),但好处是内容可以是有序的。
树 & 二叉搜索树
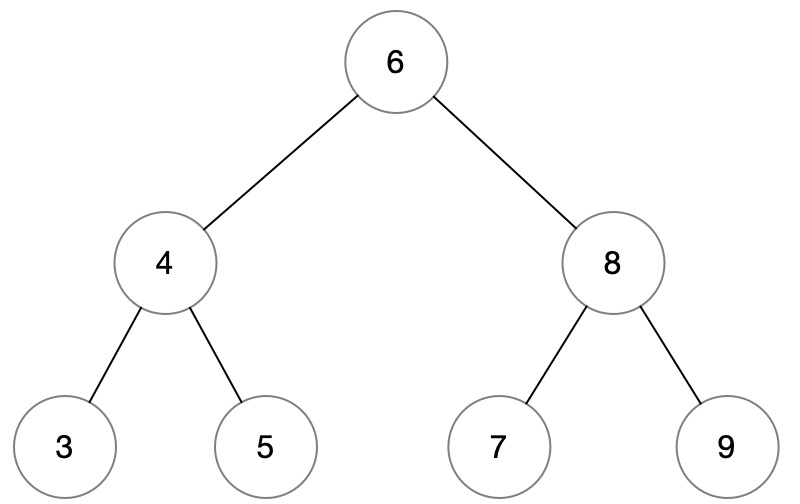
二叉搜索树是一种特殊二叉树,更复杂的还有红黑树,但这里就不深入了,只介绍二叉搜索树。
二叉搜索树满足对于任意节点,left 的所有节点 < 根节点 < right 的所有节点,注意这里是所有节点,因此在判断时需要递归考虑所有情况。
二叉搜索树的好处在于,访问、查找、插入、删除的时间复杂度均为 O(logn),因为无论何种操作都可以通过二分方式进行。但在最坏的情况会降级为 O(n),原因是多次操作后,二叉搜索树可能不再平衡,最后退化为一个链表,就变成了链表的时间复杂度。
更好的方案有 AVL 树、红黑树等,像 JAVA、C++ 标准库实现的二叉搜索树都是红黑树。
字典树
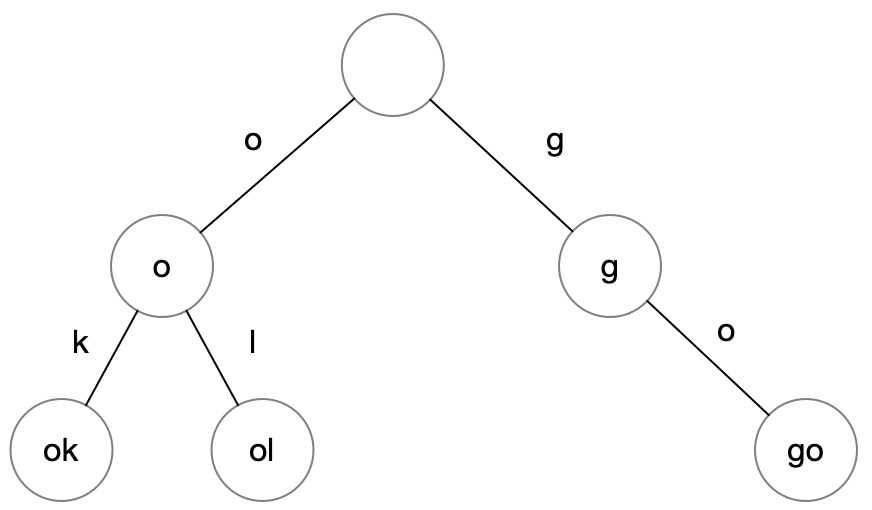
字典树多用于单词搜索场景,只要给定一个单独开头,就可以快速查找到后面有几种推荐词。
比如上面的例子,输入 “o”,就可以快速查找到后面有 “ok” 与 “ol” 两个单词。要注意的是,每个节点都要有一个属性 isEndOfWord 表示到当前为止是否为一个完整的单词:比如 go 与 good 两个都是完整的单词,但 goo 不是,因此第二个 o 与第四个 d 都有 isEndOfWord 标记,表示读到这里就查到一个完整的单词了,叶子结点的标记也可以省略。
并查集
并查集用来解决团伙问题,或者岛屿问题,即判断多个元素之间是属于某个集合。并查集的英文是 Union and Find,即归并与查找,因此并查集数据结构可以写成一个类,提供两个最基础的方法 union 与 find。
其中 union 可以将任意两个元素放在一个集合,而 find 可以查找任意元素属于哪个根集合。
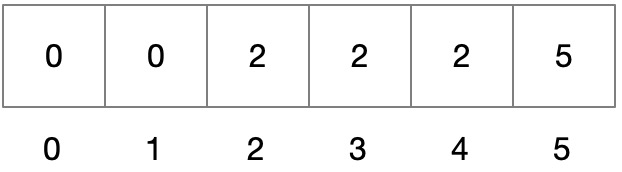
并查集使用数组的数据结构,只是有以下特殊含义,设下标为 k:
nums[k]表示其所属的集合,如果nums[k] === k表示它是这个集合的根节点。
如果要数一共有几个集合,只要数有多少满足 nums[k] === k 条件的数目即可,就像数有几个团伙,只要数有几个老大即可。
并查集的实现不同,数据也会有微妙的不同,高效的并查集在插入时,会递归将元素的值尽量指向根老大,这样查找判断时计算的快一些,但即便指向的不是根老大,也可以通过递归的方式找到根老大。
布隆过滤器
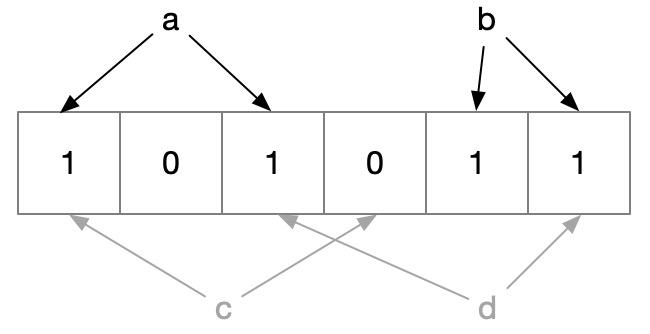
Bloom Filter 只是一个过滤器,可以用远远超过其他算法的速度把未命中的数据排除掉,但未排除的也可能实际不存在,所以需要进一步查询。
布隆过滤器是如何做到这一点的呢?就是通过二进制判断。
如上图所示,我们先存储了 a、b 两个数据,将其转化为二进制,将对应位置改为 1,那么当我们再查询 a 或 b 时,因为映射关系相同,所以查到的结果肯定存在。
但查询 c 时,发现有一项是 0,说明 c 一定不存在;但查询 d 时,恰好两个都查到是 1,但实际 d 是不存在的,这就是其产生误差的原因。
布隆过滤器在比特币与分布式系统中使用广泛,比如比特币查询交易是否在某个节点上,就先利用布隆过滤器挡一下,以快速跳过不必要的搜索,而分布式系统计算比如 Map Reduce,也通过布隆过滤器快速过滤掉不在某个节点的计算。
总结
最后给出各数据结构 “访问、查询、插入、删除” 的平均、最差时间复杂度图:
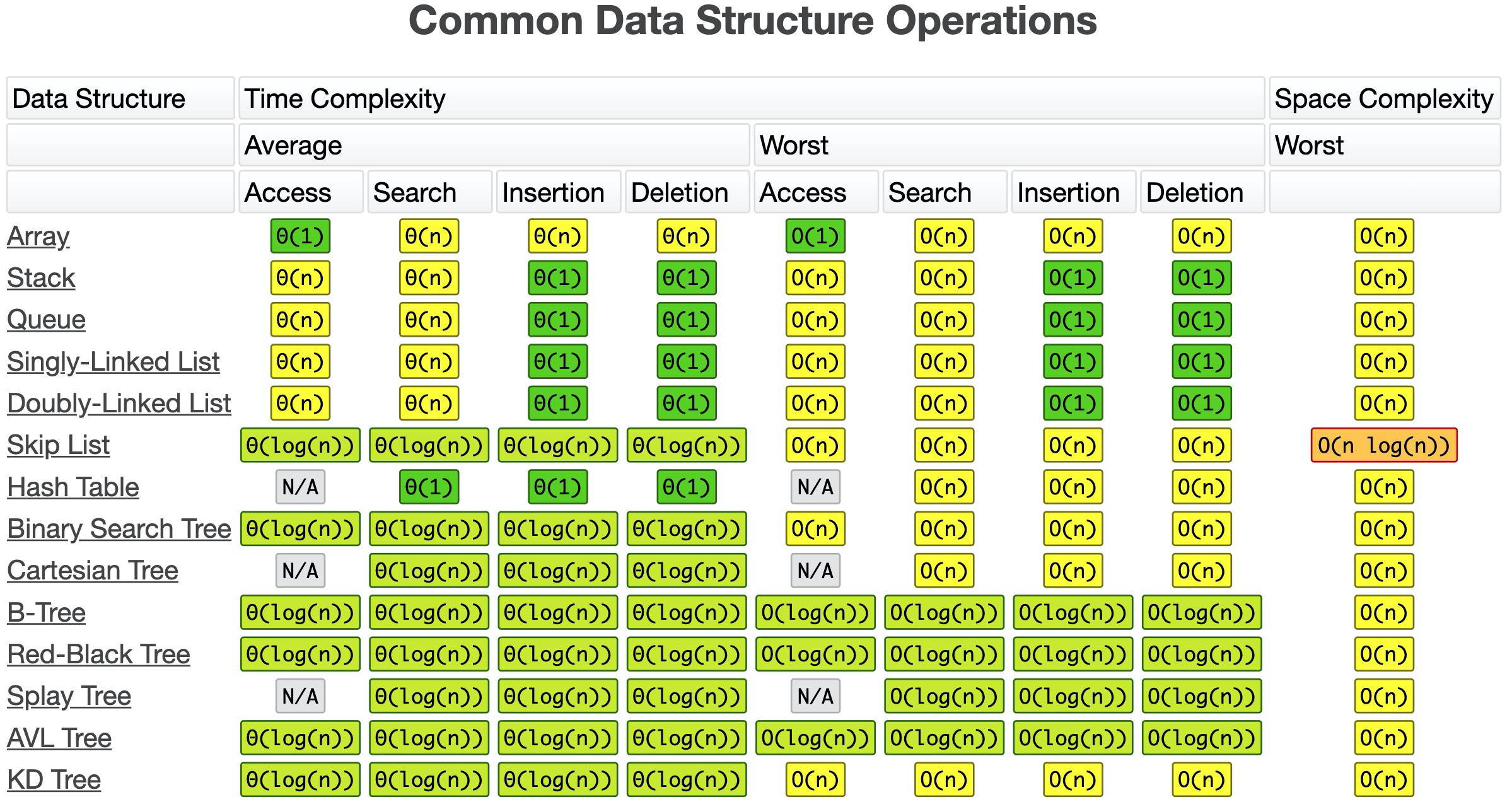
这个图来自 bigocheatsheet,你也可以点开链接直接访问。
学习了这些基础数据结构之后,希望你可以融会贯通,善于组合这些数据结构解决实际的问题,同时还要意识到没有任何一个数据结构是万能的,否则就不会有这么多数据结构需要学习了,只用一个万能的数据结构就行了。
对于数据结构的组合,我举两个例子:
第一个例子是如何以 O(1) 平均时间复杂度查询一个栈的最大或最小值。此时一个栈是不够的,需要另一个栈 B 辅助,遇到更大或更小值的时候才入栈 B,这样栈 B 的第一个数就是当前栈内最大或最小的值,查询效率是 O(1),而且只有在出栈时才需要更新,所以平均时间复杂度整体是 O(1)。
第二个例子是如何提升链表查找效率,可以通过哈希表与链表结合的思路,通过空间换时间的方式,用哈希表快速定位任意值在链表中的位置,就可以通过空间翻倍的牺牲换来插入、删除、查询时间复杂度均为 O(1)。虽然哈希表就能达到这个时间复杂度,但哈希表是无序的;虽然 HashTree 是有序的,但时间复杂度是 O(logn),所以只有通过组合 HashMap 与链表才能达到有序且时间复杂度更优,但牺牲了空间复杂度。
包括最后说的布隆过滤器也不是单独使用的,它只是一个防火墙,用极高的效率阻挡一些非法数据,但没有阻挡住的不一定就是合法的,需要进一步查询。
所以希望你能了解到各个数据结构的特征、局限以及组合的用法,相信你可以在实际场景中灵活使用不同的数据结构,以实现当前业务场景的最优解。
如果你想参与讨论,请 点击这里,每周都有新的主题,周末或周一发布。前端精读 - 帮你筛选靠谱的内容。
关注 前端精读微信公众号

版权声明:自由转载-非商用-非衍生-保持署名(创意共享 3.0 许可证)