当前期刊数: 253
pnpm 全称是 “Performant NPM”,即高性能的 npm。它结合软硬链接与新的依赖组织方式,大大提升了包管理的效率,也同时解决了 “幻影依赖” 的问题,让包管理更加规范,减少潜在风险发生的可能性。
使用 pnpm 很容易,可以使用 npm 安装:
1 | |
之后便可用 pnpm 代替 npm 命令了,比如最重要的安装包步骤,可以使用 pnpm i 代替 npm i,这样就算把 pnpm 使用起来了。
pnpm 的优势
用一个比较好记的词描述 pnpm 的优势那就是 “快、准、狠”:
- 快:安装速度快。
- 准:安装过的依赖会准确复用缓存,甚至包版本升级带来的变化都只 diff,绝不浪费一点空间,逻辑上也严丝合缝。
- 狠:直接废掉了幻影依赖,在逻辑合理性与含糊的便捷性上,毫不留情的选择了逻辑合理性。
而带来这些优势的点子,全在官网上的这张图上:
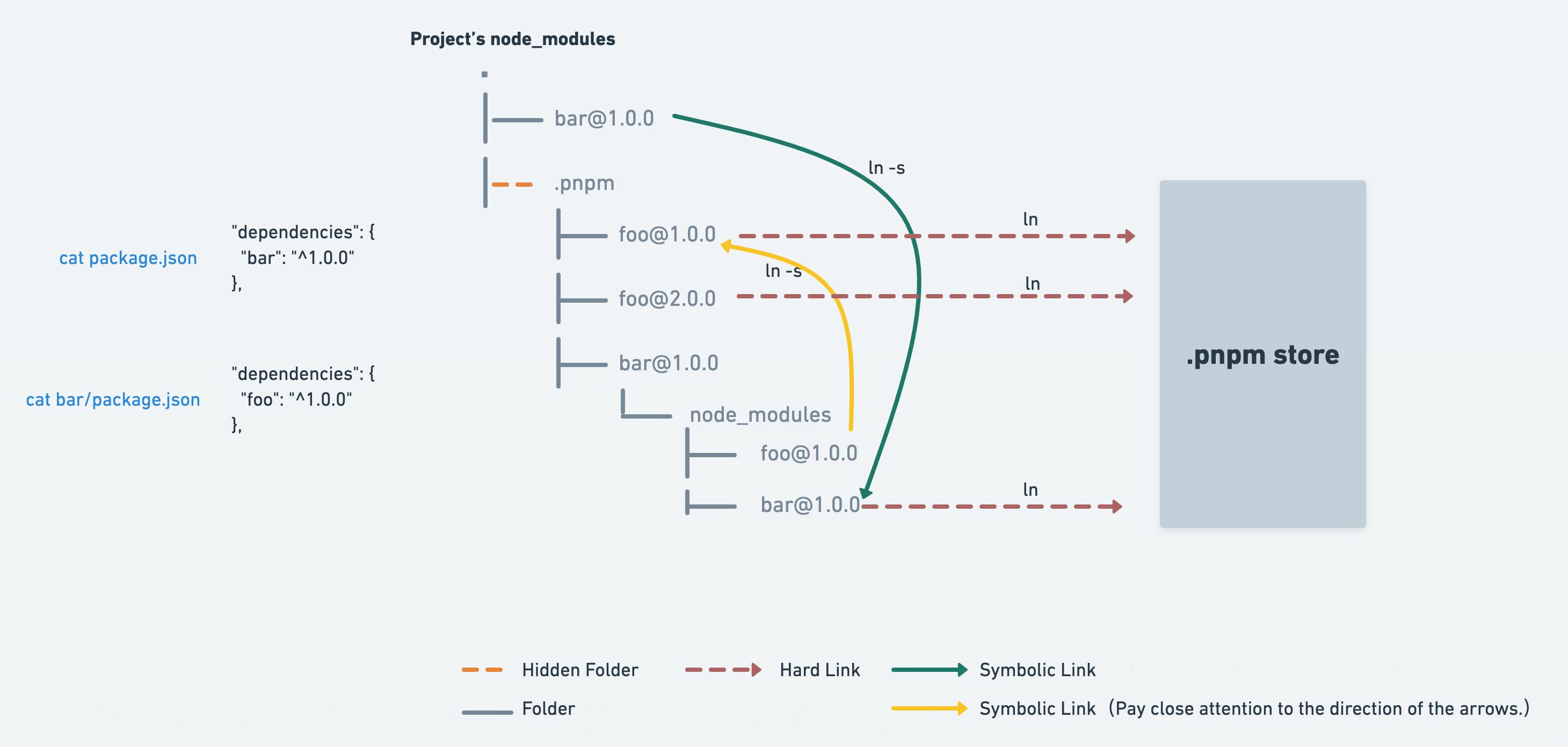
- 所有 npm 包都安装在全局目录
~/.pnpm-store/v3/files下,同一版本的包仅存储一份内容,甚至不同版本的包也仅存储 diff 内容。 - 每个项目的
node_modules下有.pnpm目录以打平结构管理每个版本包的源码内容,以硬链接方式指向 pnpm-store 中的文件地址。 - 每个项目
node_modules下安装的包结构为树状,符合 node 就近查找规则,以软链接方式将内容指向node_modules/.pnpm中的包。
所以每个包的寻找都要经过三层结构:node_modules/package-a > 软链接 node_modules/.pnpm/package-a@1.0.0/node_modules/package-a > 硬链接 ~/.pnpm-store/v3/files/00/xxxxxx。
经过这三层寻址带来了什么好处呢?为什么是三层,而不是两层或者四层呢?
依赖文件三层寻址的目的
第一层
接着上面的例子思考,第一层寻找依赖是 nodejs 或 webpack 等运行环境/打包工具进行的,他们的在 node_modules 文件夹寻找依赖,并遵循就近原则,所以第一层依赖文件势必要写在 node_modules/package-a 下,一方面遵循依赖寻找路径,一方面没有将依赖都拎到上级目录,也没有将依赖打平,目的就是还原最语义化的 package.json 定义:即定义了什么包就能依赖什么包,反之则不行,同时每个包的子依赖也从该包内寻找,解决了多版本管理的问题,同时也使 node_modules 拥有一个稳定的结构,即该目录组织算法仅与 package.json 定义有关,而与包安装顺序无关。
如果止步于此,这就是 npm@2.x 的包管理方案,但正因为 npm@2.x 包管理方案最没有歧义,所以第一层沿用了该方案的设计。
第二层
从第二层开始,就要解决 npm@2.x 设计带来的问题了,主要是包复用的问题。所以第二层的 node_modules/package-a > 软链接 node_modules/.pnpm/package-a@1.0.0/node_modules/package-a 寻址利用软链接解决了代码重复引用的问题。相比 npm@3 将包打平的设计,软链接可以保持包结构的稳定,同时用文件指针解决重复占用硬盘空间的问题。
若止步于此,也已经解决了一个项目内的包管理问题,但项目不止一个,多个项目对于同一个包的多份拷贝还是太浪费,因此要进行第三步映射。
第三层
第三层映射 node_modules/.pnpm/package-a@1.0.0/node_modules/package-a > 硬链接 ~/.pnpm-store/v3/files/00/xxxxxx 已经脱离当前项目路径,指向一个全局统一管理路径了,这正是跨项目复用的必然选择,然而 pnpm 更进一步,没有将包的源码直接存储在 pnpm-store,而是将其拆分为一个个文件块,这在后面详细讲解。
幻影依赖
幻影依赖是指,项目代码引用的某个包没有直接定义在 package.json 中,而是作为子依赖被某个包顺带安装了。代码里依赖幻影依赖的最大隐患是,对包的语义化控制不能穿透到其子包,也就是包 a@patch 的改动可能意味着其子依赖包 b@major 级别的 Break Change。
正因为这三层寻址的设计,使得第一层可以仅包含 package.json 定义的包,使 node_modules 不可能寻址到未定义在 package.json 中的包,自然就解决了幻影依赖的问题。
但还有一种更难以解决的幻影依赖问题,即用户在 Monorepo 项目根目录安装了某个包,这个包可能被某个子 Package 内的代码寻址到,要彻底解决这个问题,需要配合使用 Rush,在工程上通过依赖问题检测来彻底解决。
peer-dependences 安装规则
pnpm 对 peer-dependences 有一套严格的安装规则。对于定义了 peer-dependences 的包来说,意味着为 peer-dependences 内容是敏感的,潜台词是说,对于不同的 peer-dependences,这个包可能拥有不同的表现,因此 pnpm 针对不同的 peer-dependences 环境,可能对同一个包创建多份拷贝。
比如包 bar peer-dependences 依赖了 baz^1.0.0 与 foo^1.0.0,那我们在 Monorepo 环境两个 Packages 下分别安装不同版本的包会如何呢?
1 | |
结果是这样(引用官网文档例子):
1 | |
可以看到,安装了两个相同版本的 foo,虽然内容完全一样,但却分别拥有不同的名称:foo@1.0.0_bar@1.0.0+baz@1.0.0、foo@1.0.0_bar@1.0.0+baz@1.1.0。这也是 pnpm 规则严格的体现,任何包都不应该有全局副作用,或者考虑好单例实现,否则可能会被 pnpm 装多次。
硬连接与软链接的原理
要理解 pnpm 软硬链接的设计,首先要复习一下操作系统文件子系统对软硬链接的实现。
硬链接通过 ln originFilePath newFilePath 创建,如 ln ./my.txt ./hard.txt,这样创建出来的 hard.txt 文件与 my.txt 都指向同一个文件存储地址,因此无论修改哪个文件,都因为直接修改了原始地址的内容,导致这两个文件内容同时变化。进一步说,通过硬链接创建的 N 个文件都是等效的,通过 ls -li ./ 查看文件属性时,可以看到通过硬链接创建的两个文件拥有相同的 inode 索引:
1 | |
其中第三个参数 2 表示该文件指向的存储地址有两个硬链接引用。硬链接如果要指向目录就麻烦多了,第一个问题是这样会导致文件的父目录有歧义,同时还要将所有子文件都创建硬链接,实现复杂度较高,因此 Linux 并没有提供这种能力。
软链接通过 ln -s originFilePath newFilePath 创建,可以认为是指向文件地址指针的指针,即它本身拥有一个新的 inode 索引,但文件内容仅包含指向的文件路径,如:
1 | |
源文件被删除时,软链接也会失效,但硬链接不会,软链接可以对文件夹生效。因此 pnpm 虽然采用了软硬结合的方式实现代码复用,但软链接本身也几乎不会占用多少额外的存储空间,硬链接模式更是零额外内存空间占用,所以对于相同的包,pnpm 额外占用的存储空间可以约等于零。
全局安装目录 pnpm-store 的组织方式
pnpm 在第三层寻址时采用了硬链接方式,但同时还留下了一个问题没有讲,即这个硬链接目标文件并不是普通的 NPM 包源码,而是一个哈希文件,这种文件组织方式叫做 content-addressable(基于内容的寻址)。
简单来说,基于内容的寻址比基于文件名寻址的好处是,即便包版本升级了,也仅需存储改动 Diff,而不需要存储新版本的完整文件内容,在版本管理上进一步节约了存储空间。
pnpm-store 的组织方式大概是这样的:
1 | |
也就是采用文件内容寻址,而非文件位置寻址的存储方式。之所以能采用这种存储方式,是因为 NPM 包一经发布内容就不会再改变,因此适合内容寻址这种内容固定的场景,同时内容寻址也忽略了包的结构关系,当一个新包下载下来解压后,遇到相同文件 Hash 值时就可以抛弃,仅存储 Hash 值不存在的文件,这样就自然实现了开头说的,pnpm 对于同一个包不同的版本也仅存储其增量改动的能力。
总结
pnpm 通过三层寻址,既贴合了 node_modules 默认寻址方式,又解决了重复文件安装的问题,顺便解决了幻影依赖问题,可以说是包管理的目前最好的创新,没有之一。
但其苛刻的包管理逻辑,使我们单独使用 pnpm 管理大型 Monorepo 时容易遇到一些符合逻辑但又觉得别扭的地方,比如如果每个 Package 对于同一个包的引用版本产生了分化,可能会导致 Peer Deps 了这些包的包产生多份实例,而这些包版本的分化可能是不小心导致的,我们可能需要使用 Rush 等 Monorepo 管理工具来保证版本的一致性。
如果你想参与讨论,请 点击这里,每周都有新的主题,周末或周一发布。前端精读 - 帮你筛选靠谱的内容。
关注 前端精读微信公众号

版权声明:自由转载-非商用-非衍生-保持署名(创意共享 3.0 许可证)