当前期刊数: 62
1 引言
本期精读的文章是:JS 引擎基础之 Shapes and Inline Caches
一起了解下 JS 引擎是如何运作的吧!
JS 的运作机制可以分为 AST 分析、引擎执行两个步骤:

JS 源码通过 parser(分析器)转化为 AST(抽象语法树),再经过 interpreter(解释器)解析为 bytecode(字节码)。
为了提高运行效率,optimizing compiler(优化编辑器)负责生成 optimized code(优化后的机器码)。
本文主要从 AST 之后说起。
2 概述
JS 的解释器、优化器
JS 代码可能在字节码或者优化后的机器码状态下执行,而生成字节码速度很快,而生成机器码就要慢一些了。

V8 也类似,V8 将 interpreter 称为 Ignition(点火器),将 optimizing compiler 称为 TurboFan(涡轮风扇发动机)。

可以理解为将代码先点火启动后,逐渐进入涡轮发动机提速。
代码先快速解析成可执行的字节码,在执行过程中,利用执行中获取的数据(比如执行频率),将一些频率高的方法,通过优化编译器生成机器码以提速。

火狐使用的 Mozilla 引擎有一点点不同,使用了两个优化编译器,先将字节码优化为部分机器码,再根据这个部分优化后的代码运行时拿到的数据进行最终优化,生成高度优化的机器码,如果优化失败将会回退到部分优化的机器码。
笔者:不同前端引擎对 JS 优化方式大同小异,后面会继续列举不同前端引擎在解析器、编译器部分优化的方式。

微软的 Edge 浏览器,使用的 Chakra 引擎,优化方式与 Mozilla 很像,区别是第二个最终优化的编译器同时接收字节码和部分优化的机器码产生的数据,并且在优化失败后回退到第一步字节码而不是第二步。
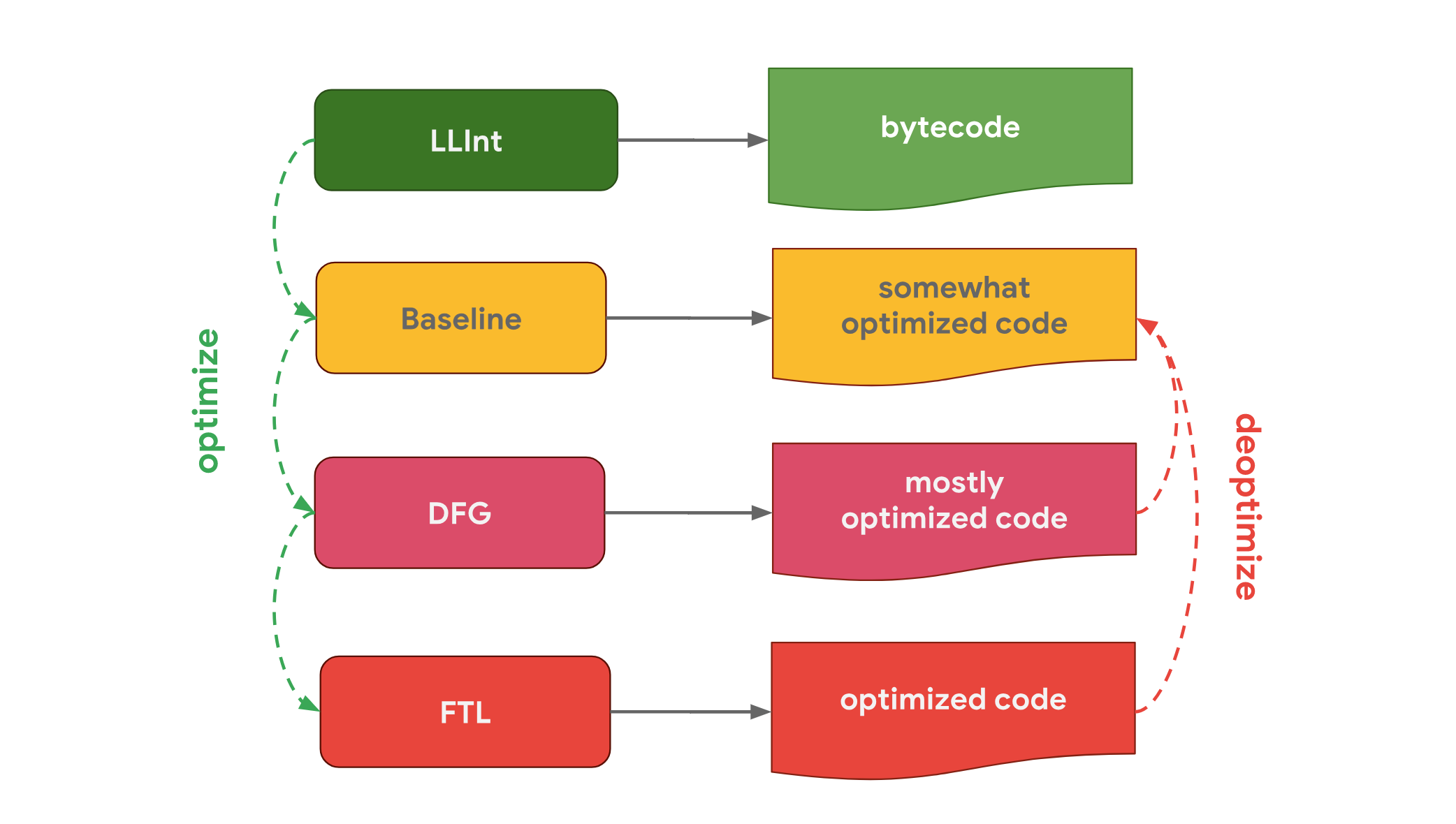
Safari、React Native 使用的 JSC 引擎则更为极端,使用了三个优化编译器,其优化是一步步渐进的,优化失败后都会回退到第一步部分优化的机器码。
为什么不同前端引擎会使用不同的优化策略呢?这是由于 JS 要么使用解释器快速执行(生成字节码),或者优化成机器码后再执行,但优化消耗时间的并不总是小于字节码低效运行损耗的时间,所以有些引擎选择了多个优化编译器,逐层优化,尽可能在解析时间与执行效率中找到一个平衡点。
JS 的对象模型
JS 是基于面向对象的,那么 JS 引擎是如何实现 JS 对象模型的呢?他们用了哪些技巧加速访问 JS 对象的属性?
和解析器、优化器一样,大部分主流 JS 引擎在对象模型实现上也很类似。
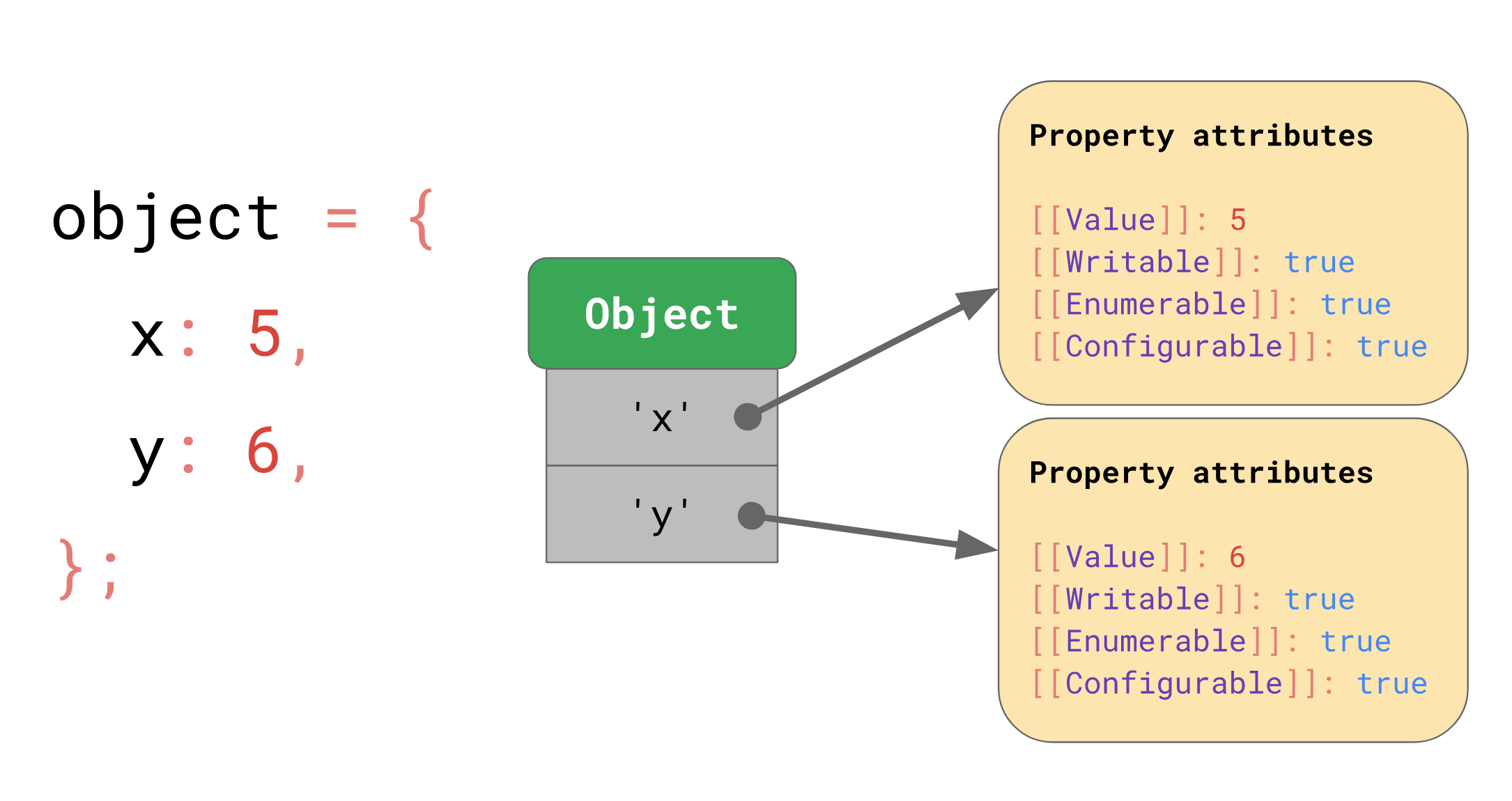
ECMAScript 规范确定了对象模型就是一个以字符串为 key 的字典,除了其值以外,还定义了 Writeable Enumerable Configurable 这些配置,表示这个 key 能否被重写、遍历访问、配置。
虽然规范定义了 [[]] 双括号的写法,那这不会暴露给用户,暴露给用户的是 Object.getOwnPropertyDescriptor 这个 API,可以拿到某个属性的配置。
在 JS 中,数组是对象的特殊场景,相比对象,数组拥有特定的下标,根据 ECMAScript 规范规定,数组下标的长度最大为 2³²−1。同时数组拥有 length 属性:

length 只是一个不可枚举、不可配置的属性,并且在数组赋值时,会自动更新数值:

所以数组是特殊的对象,结构完全一致。
属性访问效率优化
属性访问是最常见的,所以 JS 引擎必须对属性访问做优化。
Shapes
JS 编程中,给不同对象相同的 key 名很常见,访问不同对象的同一个 propertyKey 也很常见:
1 | |
这时 object1 与 object2 拥有一个相同的 shape。拿拥有 x、y 属性的对象来看:
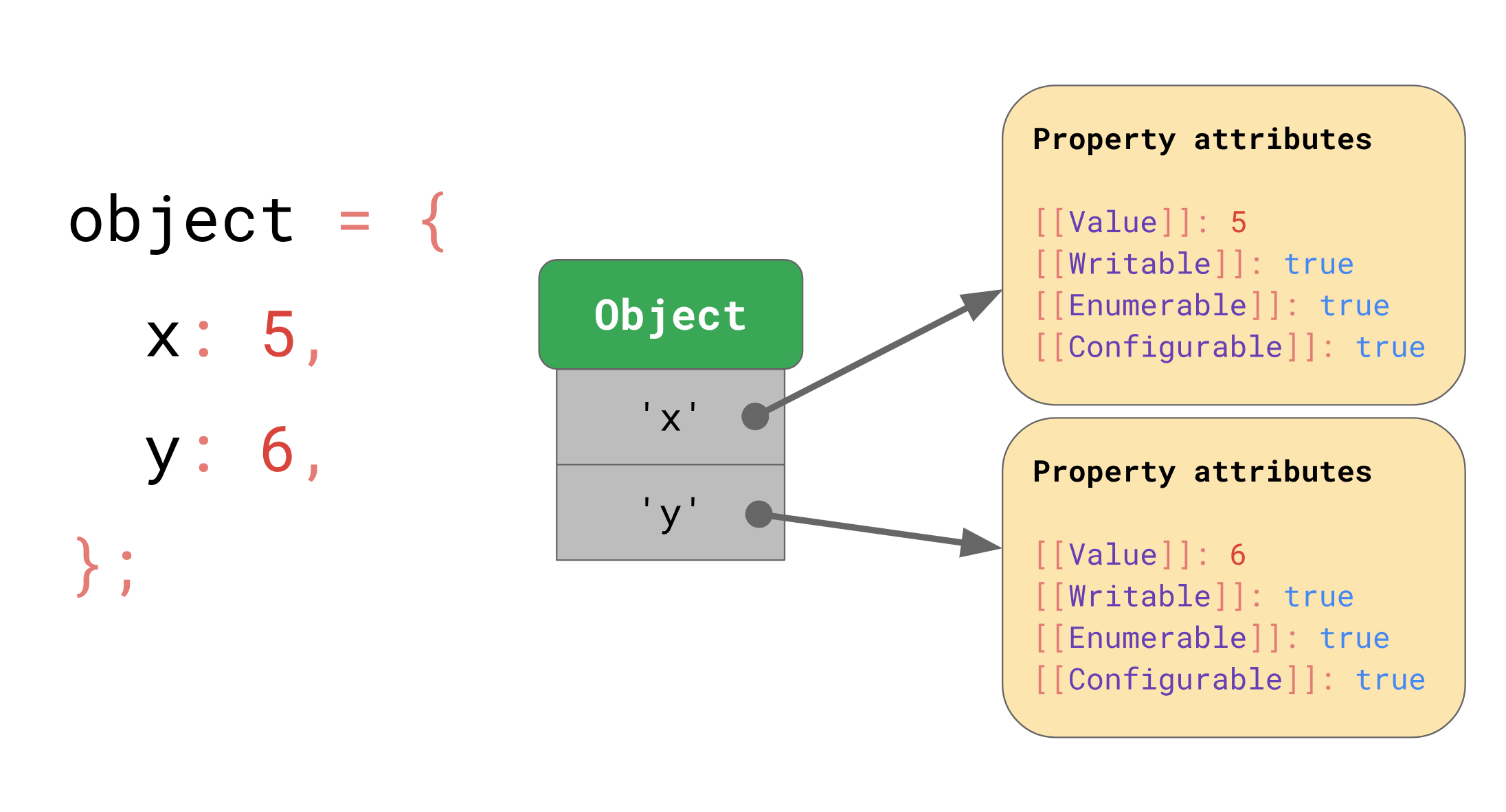
如果访问 object.y,JS 引擎会先找到 key y,再查找 [[value]]。
如果将属性值也存储在 JSObject 中,像 object1 object2 就会出现许多冗余数据,因此引擎单独存储 Shape,与真实对象隔离:

这样具有相同结构的对象可以共享 Shape。所有 JS 引擎都是用这种方式优化对象,但并不都称为 Shape,这里就不详细罗列了,可以去原文查看在各引擎中 Shape 的别名。
Transition chains 和 Transition trees
如果给一个对象增加了 key,JS 引擎如何生成新的 Shape 呢?
这种 Shape 链式创建的过程,称为 Transition chains:

开始创建空对象时,JSObject 和 Shape 都是空,当为 x 赋值 5 时,在 JSObject 下标 0 的位置添加了 5,并且 Shape 指向了拥有字段 x 的 Shape(x),当赋值 y 为 6 时,在 JSObject 下标 1 的位置添加了 6,并将 Shape 指向了拥有字段 x 和 y 的 Shape(x, y)。
而且可以再优化,Shape(x, y) 由于被 Shape(x) 指向,所以可以省略 x 这个属性:

笔者:当然这里说的主要是优化技巧,我们可以看出来,JS 引擎在做架构设计时没有考虑优化问题,而在架构设计完后,再回过头对时间和空间进行优化,这是架构设计的通用思路。
如果没有连续的父 Shape,比如分别创建两个对象:
1 | |
这时要通过 Transition trees 来优化:

可以看到,两个 Shape(x) Shape(y) 分别继承 Shape(empty)。当然也不是任何时候都会创建空 Shape,比如下面的情况:
1 | |
生成的 Shape 如下图所示:

可以看到,由于 object2 并不是从空对象开始的,所以并不会从 Shape(empty) 开始继承。
Inline Caches
大概可以翻译为“局部缓存”,JS 引擎为了提高对象查找效率,需要在局部做高效缓存。
比如有一个函数 getX,从 o.x 获取值:
1 | |
JSC 引擎 生成的字节码结构是这样的:

get_by_id 指令是获取 arg1 参数指向的对象 x,并存储在 loc0,第二步则返回 loc0。
当执行函数 getX({ x: 'a' }) 时,引擎会在 get_by_id 指令中缓存这个对象的 Shape:

这个对象的 Shape 记录了自己拥有的字段 x 以及其对应的下标 offset:
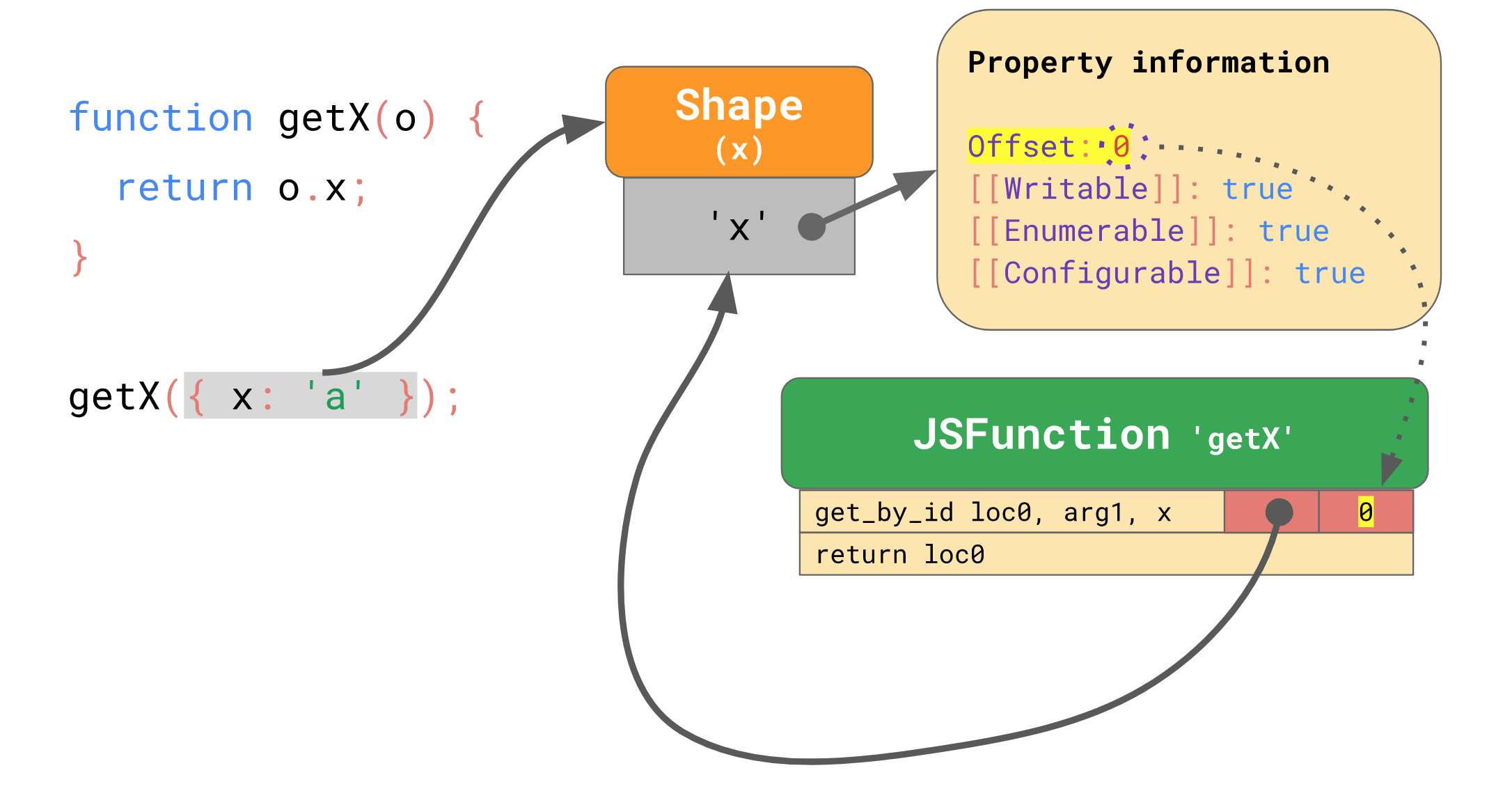
执行 get_by_id 时,引擎从 Shape 查找下标,找到 x,这就是 o.x 的查找过程。但一旦找到,引擎就会将 Shape 保存的 offset 缓存起来,下次开始直接跳过 Shape 这一步:
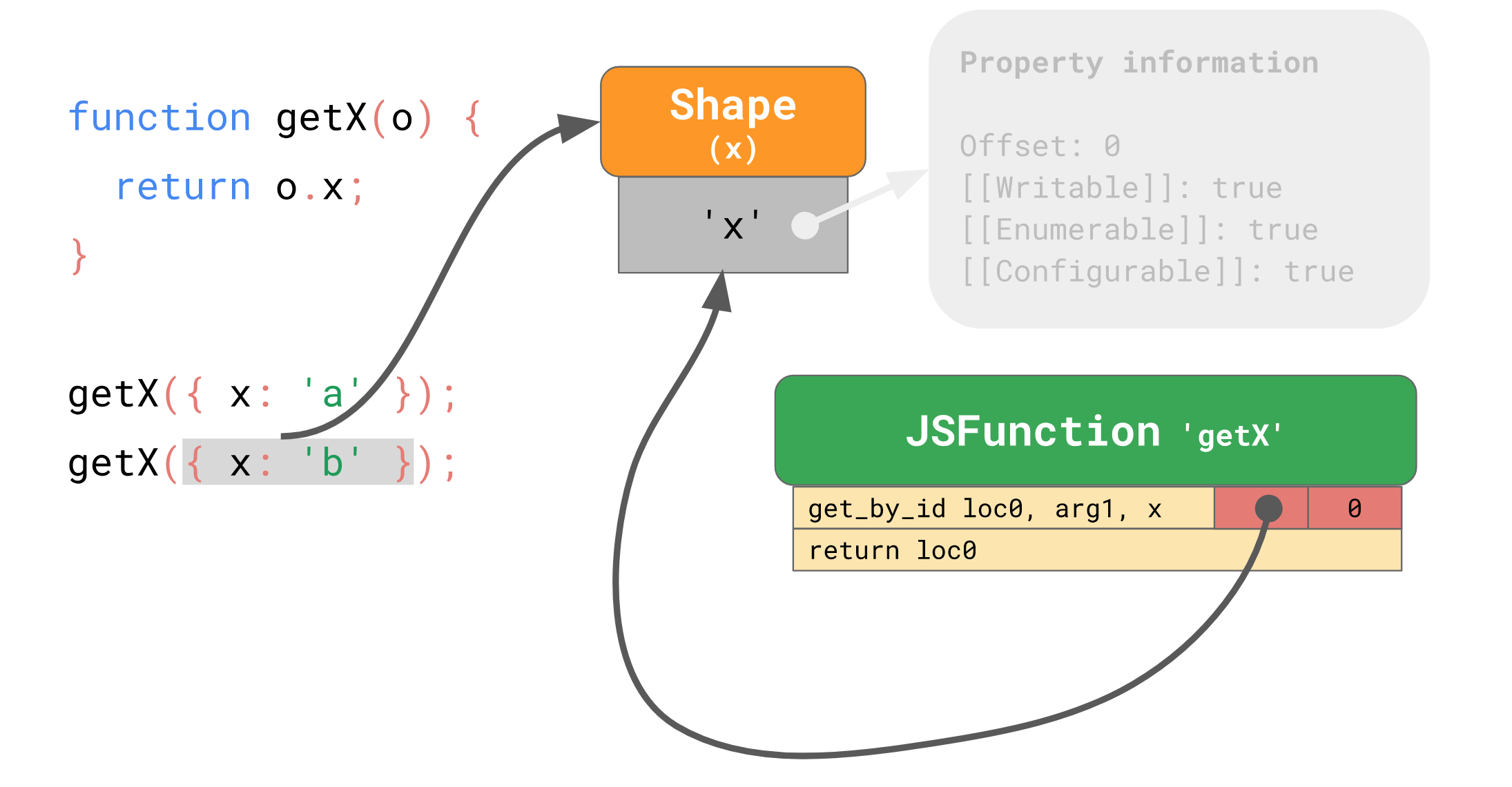
以后访问 o.x 时,只要 Shape 相同,引擎直接从 get_by_id 指令中缓存的下标中可以直接命中要查找的值,而这个缓存在指令中的下标就是 Inline Cache.
数组存储优化
和对象一样,数组的存储也可以被优化,而由于数组的特殊性,不需要为每一项数据做完整的配置。
比如这个数组:
1 | |
JS 引擎同样通过 Shape 与数据分离的方式存储:
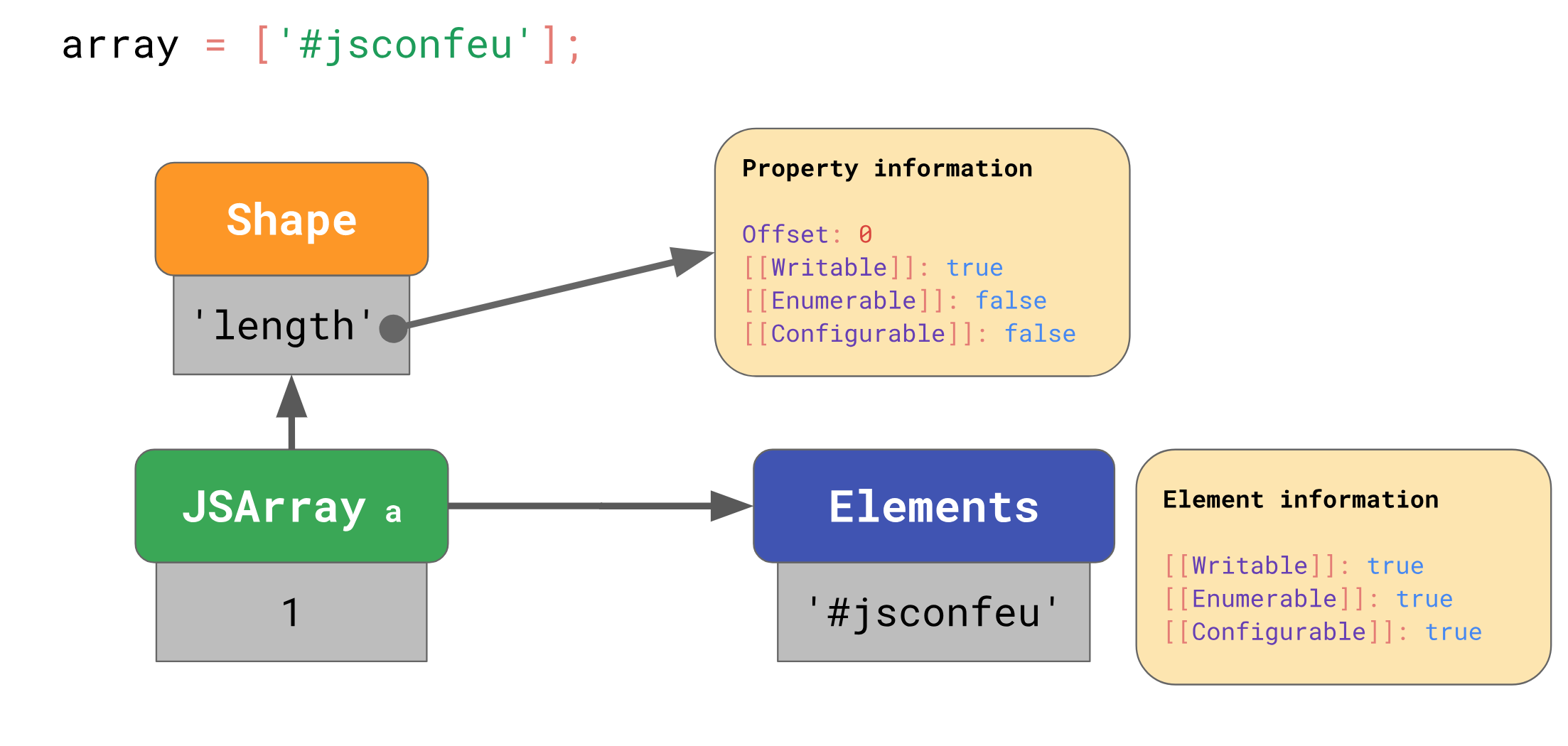
JS 引擎将数组的值单独存储在 Elements 结构中,而且它们通常都是可读可配置可枚举的,所以并不会像对象一样,为每个元素做配置。
但如果是这种例子:
1 | |
JS 引擎会存储一个 Dictionary Elements 类型,为每个数组元素做配置:

这样数组的优化就没有用了,后续的赋值都会基于这种比较浪费空间的 Dictionary Elements 结构。所以永远不要用 Object.defineProperty 操作数组。
通过对 JS 引擎原理的认识,作者总结了下面两点代码中的注意事项:
- 尽量以相同方式初始化对象,因为这样会生成较少的
Shapes。 - 不要混淆对象的
propertyKey与数组的下标,虽然都是用类似的结构存储,但 JS 引擎对数组下标做了额外优化。
3 精读
这次原理系列解读是针对 JS 引擎执行优化这个点的,而网页渲染流程大致如下:

可以看到 Script 在整个网页解析链路中位置是比较靠前的,JS 解析效率会直接影响网页的渲染,所以 JS 引擎通过解释器(parser)和优化器(optimizing compiler)尽可能对 JS 代码提效。
Shapes
需要特别说明的是,Shapes 并不是原型链,原型链是面向开发者的概念,而 Shapes 是面向 JS 引擎的概念。
比如如下代码:
1 | |
显然对象 a b c 之间是没有关联的,但共享一个 Shapes。
另外理解引擎的概念有助于我们站在语法层面对立面的角度思考问题:在 JS 学习阶段,我们会执着于思考如下几种创建对象方式的异同:
1 | |
比如上面四种情况,我们要理解在什么情况下,用何种方式创建对象性能最优。
但站在 JS 引擎优化角度去考虑,JS 引擎更希望我们都通过 const a = {} 这种看似最没有难度的方式创建对象,因为可以共享 Shape。而与其他方式混合使用,可能在逻辑上做到了优化,但阻碍了 JS 引擎做自动优化,可能会得不偿失。
Inline Caches
对象级别的优化已经很极致了,工程代码中也没有机会帮助 JS 引擎做得更好,值得注意的是不要对数组使用 Object 对象下的方法,尤其是 defineProperty,因为这会让 JS 引擎在存储数组元素时,使用 Dictionary Elements 结构替代 Elements,而 Elements 结构是共享 PropertyDescriptor 的。
但也有难以避免的情况,比如使用 Object.defineProperty 监听数组变化时,就不得不破坏 JS 引擎渲染了。
笔者写 dob 的时候,使用 proxy 监听数组变化,这并不会改变 Elements 的结构,所以这也从另一个侧面证明了使用 proxy 监听对象变化比 Object.defineProperty 更优,因为 Object.defineProperty 会破坏 JS 引擎对数组做的优化。
4 总结
本文主要介绍了 JS 引擎两个概念: Shapes 与 Inline Caches,通过认识 JS 引擎的优化方式,在编程中需要注意以下两件事:
- 尽量以相同方式初始化对象,因为这样会生成较少的
Shapes。 - 不要混淆对象的
propertyKey与数组的下标,虽然都是用类似的结构存储,但 JS 引擎对数组下标做了额外优化。
5 更多讨论
讨论地址是:精读《JS 引擎基础之 Shapes and Inline Caches》 · Issue ##91 · dt-fe/weekly
如果你想参与讨论,请点击这里,每周都有新的主题,周末或周一发布。